【导读】本文介绍了如何通过开源工具构建基于Zabbix官方文档的知识库问答系统并嵌入至Zabbix前端,详细阐述了系统环境搭建与基础安装过程。
【作者】程哲 Zabbix开源社区代表 2024Zabbix中国峰会演讲嘉宾 Zabbix7.0中文手册译者
目录
1 介绍
2 硬件需求
3 安装部署
4 配置Maxkb
5 嵌入至Zabbix前端
6 效果展示
7 Q&A
1 介绍
1.1 背景
构建基于Zabbix官方文档的知识库问答系统,利用语言模型和检索增强生成技术,可以理解用户提问并检索相关信息给出准确答案,提高用户检索手册效率和使用体验。
1.2 系统特点
① 基于开源技术,支持容器化部署,简单上手
② 高效的知识整合与检索
③ 支持私有化部署,数据可以完全在内网处理,安全可靠
1.3 系统架构
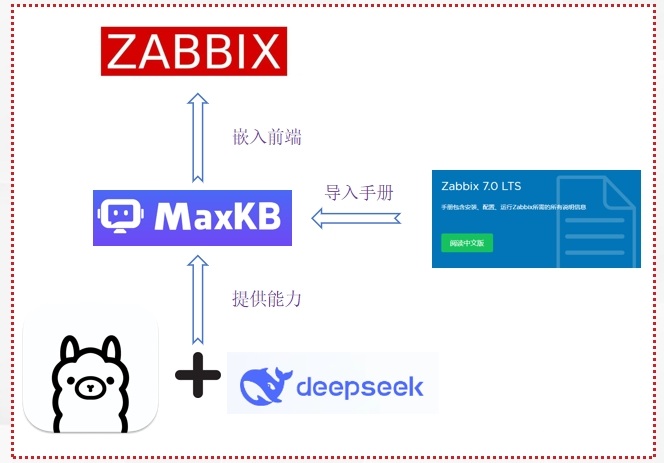
2 硬件需求
Server-02 的硬件有两种选择方案。当私有化部署大模型时硬件需求无法得到满足时,建议通过 API 调用公有大模型,否则可能会造成使用感知下降,进而带来不佳的体验。
3 安装部署
3.1 在Server1上部署Zabbix7.0
本次Zabbix部署环境选用CentOS Stream 9+mysql
3.1.1 安装相关软件
rpm -Uvh https://repo.zabbix.com/zabbix/7.0/centos/9/x86_64/zabbix-release-7.0-5.el9.noarch.rpm
dnf install zabbix-server-mysql zabbix-web-mysql zabbix-nginx-conf zabbix-sql-scripts zabbix-selinux-policy zabbix-agent
dnf install mysql-server
systemctl start mysqld && systemctl enable mysqld3.1.2 登录 MySQL 创建用户和库
mysql
mysql> create database zabbix character set utf8mb4 collate utf8mb4_bin;
mysql> create user zabbix@localhost identified by 'Zabbix@2024#';
mysql> grant all privileges on zabbix.* to zabbix@localhost;
mysql> set global log_bin_trust_function_creators = 1;
mysql> quit;3.1.3 导入数据库,修改配置文件
zcat /usr/share/zabbix-sql-scripts/mysql/server.sql.gz | mysql --default-character-set=utf8mb4 -uzabbix -p zabbix
vi /etc/zabbix/zabbix_server.conf
DBPassword=Zabbix@2024#
CacheSize=128M
vi /etc/nginx/nginx.conf # 80 改为 8080
listen 8080;
listen [::]:8080;
vi /etc/nginx/conf.d/zabbix.conf # 取消注释下面2行
listen 80;
server_name example.com;
systemctl restart zabbix-server zabbix-agent nginx php-fpm
systemctl enable zabbix-server zabbix-agent nginx php-fpm3.2 在Server2上安装Maxkb
部署环境选用CentOS系统,安装Maxkb前请提前安装好Docker,一键安装Maxkb命令如下:
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data -v ~/.python-packages:/opt/maxkb/app/sandbox/python-packages cr2.fit2cloud.com/1panel/maxkb3.3 申请deepseek大模型API授权(选做,硬件配置不足时推荐)
官方API申请地址:https://platform.deepseek.com/sign_in
建议选择DeepSeek官方API,不仅能享受稳定可靠的服务,成本方面每百万 tokens 仅需 8 元,实际测试调用30次API,仅耗费20000 Tokens,约0.1元, 性价比极高。
3.4 在Server2上安装Ollama(选做,本地部署大模型参考)
① 下载Ollama:
mkdir /home/ollama && cd /home/ollama
wget https://github.moeyy.xyz/https://github.com/ollama/ollama/releases/download/v0.3.11/ollama-linux-amd64.tgz② 下载安装脚本:
wget https://ollama.com/install.sh③ 编辑官方安装脚本,将脚本中下载源替换为已经从Github中下载到本地的安装文件
vi install.sh④ 请将脚本71-94行替换为如下内容
status "Installing ollama to $OLLAMA_INSTALL_DIR"
$SUDO install -o0 -g0 -m755 -d $BINDIR
$SUDO install -o0 -g0 -m755 -d "$OLLAMA_INSTALL_DIR"
if [ -f "/home/ollama/ollama-linux-amd64.tgz" ]; then
status "Using locally downloaded Linux ${ARCH} bundle"
$SUDO tar -xzf /home/ollama/ollama-linux-amd64.tgz -C "$OLLAMA_INSTALL_DIR"
BUNDLE=1
if [ "$OLLAMA_INSTALL_DIR/bin/ollama"!= "$BINDIR/ollama" ]; then
status "Making ollama accessible in the PATH in $BINDIR"
$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi
else
status "Downloading Linux ${ARCH} CLI"
curl --fail --show-error --location --progress-bar -o "$TEMP_DIR/ollama" "https://ollama.com/download/ollama-linux-${ARCH}${VER_PARAM}"
$SUDO install -o0 -g0 -m755 $TEMP_DIR/ollama $OLLAMA_INSTALL_DIR/ollama
BUNDLE=0
if [ "$OLLAMA_INSTALL_DIR/ollama"!= "$BINDIR/ollama" ]; then
status "Making ollama accessible in the PATH in $BINDIR"
$SUDO ln -sf "$OLLAMA_INSTALL_DIR/ollama" "$BINDIR/ollama"
fi
fi⑤ 执行安装脚本即可
chmod +x install.sh && sh install.sh 注:本次下载ollama模型使用了GitHub 文件加速下载,也可直接从ollama官网下载安装,命令为:
curl -fsSL https://ollama.com/install.sh | sh⑥ 修改Ollama配置文件
vi /etc/systemd/system/ollama.service在[Service]下面加上:
Environment="OLLAMA_HOST=0.0.0.0:11434"⑦ 重启ollama
systemctl daemon-reload && systemctl restart ollama⑧ 下载并运行deepseek-r1:7b
ollama run deepseek-r1:7b4 配置Maxkb
通过浏览器访问 MaxKB:
http://目标服务器 IP 地址:8080
默认登录信息
用户名:admin
默认密码:MaxKB@123..4.1 配置模型(公有大模型API)
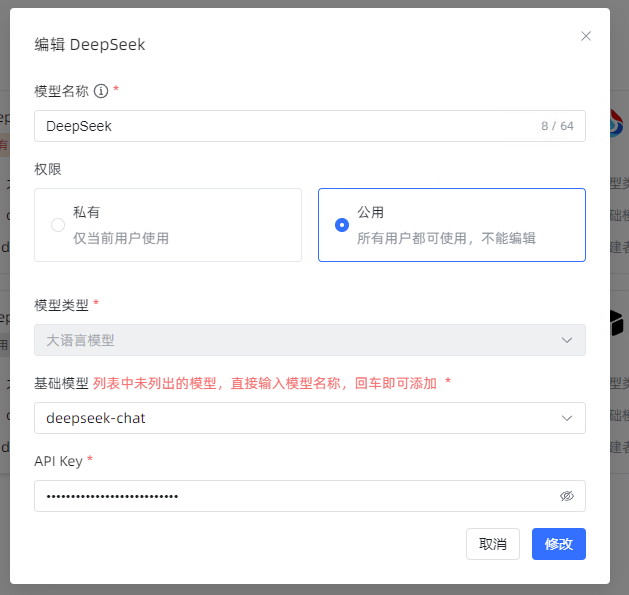
进入系统管理-模型设置-添加模型列表中,列出了所有可调用模型,选择添加deepseek模型,模型名称填写deepseek-api,模型类型选择大语言模型,基础模型选择“deepseek-chat”,最后将申请到的API Key填入即可。
4.2 配置模型(私有部署大模型)
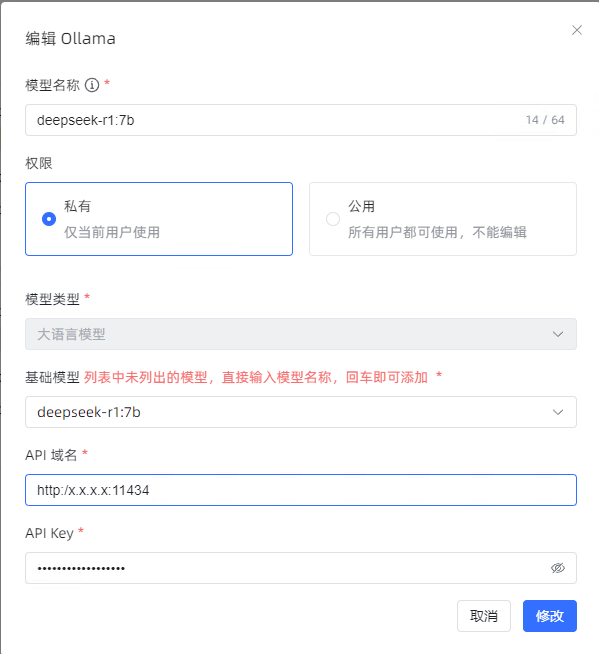
进入系统管理-模型设置-添加模型列表中,列出了所有可调用模型,选择添加Ollama模型,名称填写deepseek-api,模型类型选择大语言模型,基础模型手动输入“deepseek-r1:7b”,API域名填写部署ollama的服务器私网ip+11434端口好,API Key未设置的话可随意输入任意字符,点击确定即可。
4.3 新建知识库并配置
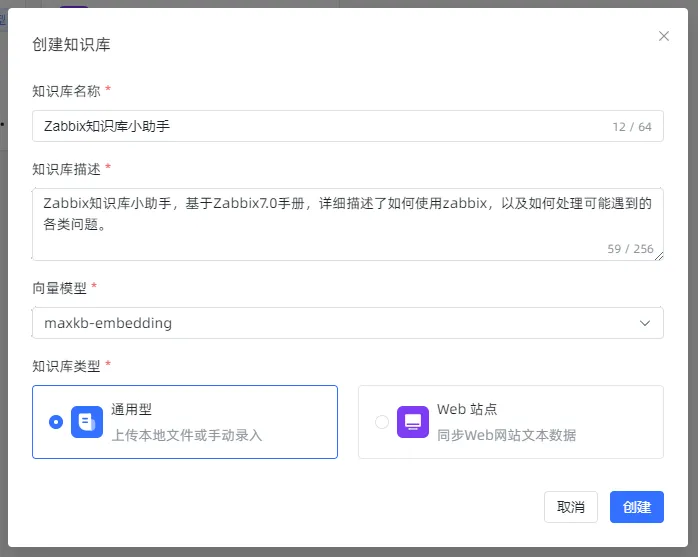
选择知识库-创建知识库,有两种类型可选,通用型可上传或手动录入文档,Web站点可以直接同步网站文本数据,本次上传本地Zabbix-7.0手册pdf文档,上传完后会自动进行索引并进行向量化处理,等待索引完成即可。
4.4 新建应用并配置
选择应用-创建应用,输入自定义名称及描述,选择简单配置即可,如需自定义工作流也可进行高级编排,本文不再展开讨论。
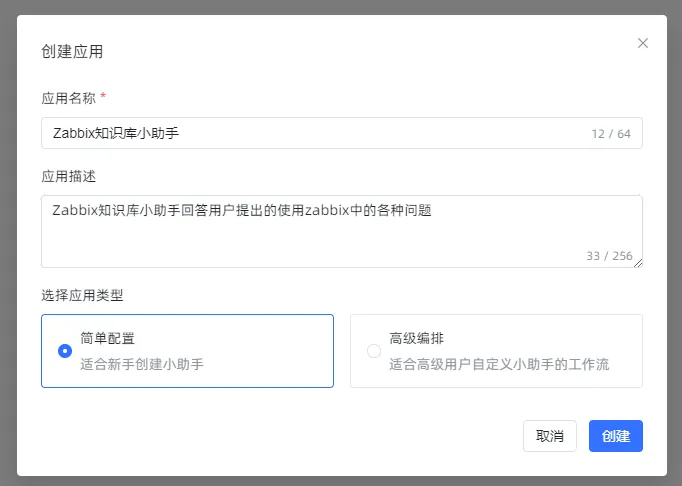
在设置中根据实际情况修改AI模型及自定义开场白,并关联已上传的知识库,可在参数设置中对检索模式和召回分段进行设置,测试并调整至合适效果即可。
5 嵌入至Zabbix前端
在Maxkb中找到应用-Zabbix知识库小助手-概览-嵌入第三方
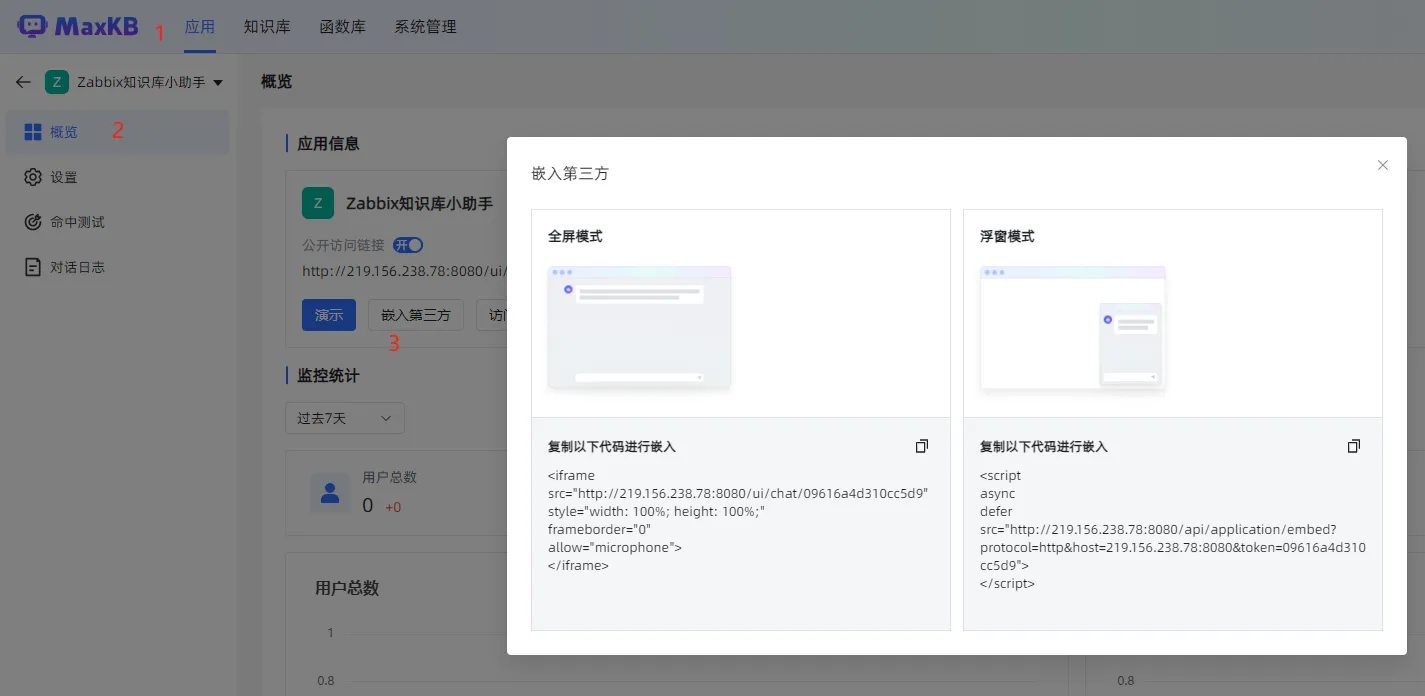
找到浮窗模式,复制所有代码,编辑Zabbix前端文件
vi /usr/share/zabbix/include/page_footer.php +62在第62行加入
echo ' *******(此处为maxkb中复制的代码)';
vi /usr/share/zabbix/app/views/layout.htmlpage.php +96在第96行加入
echo ' *******(此处为maxkb中复制的代码)';
最后重启zabbix即可
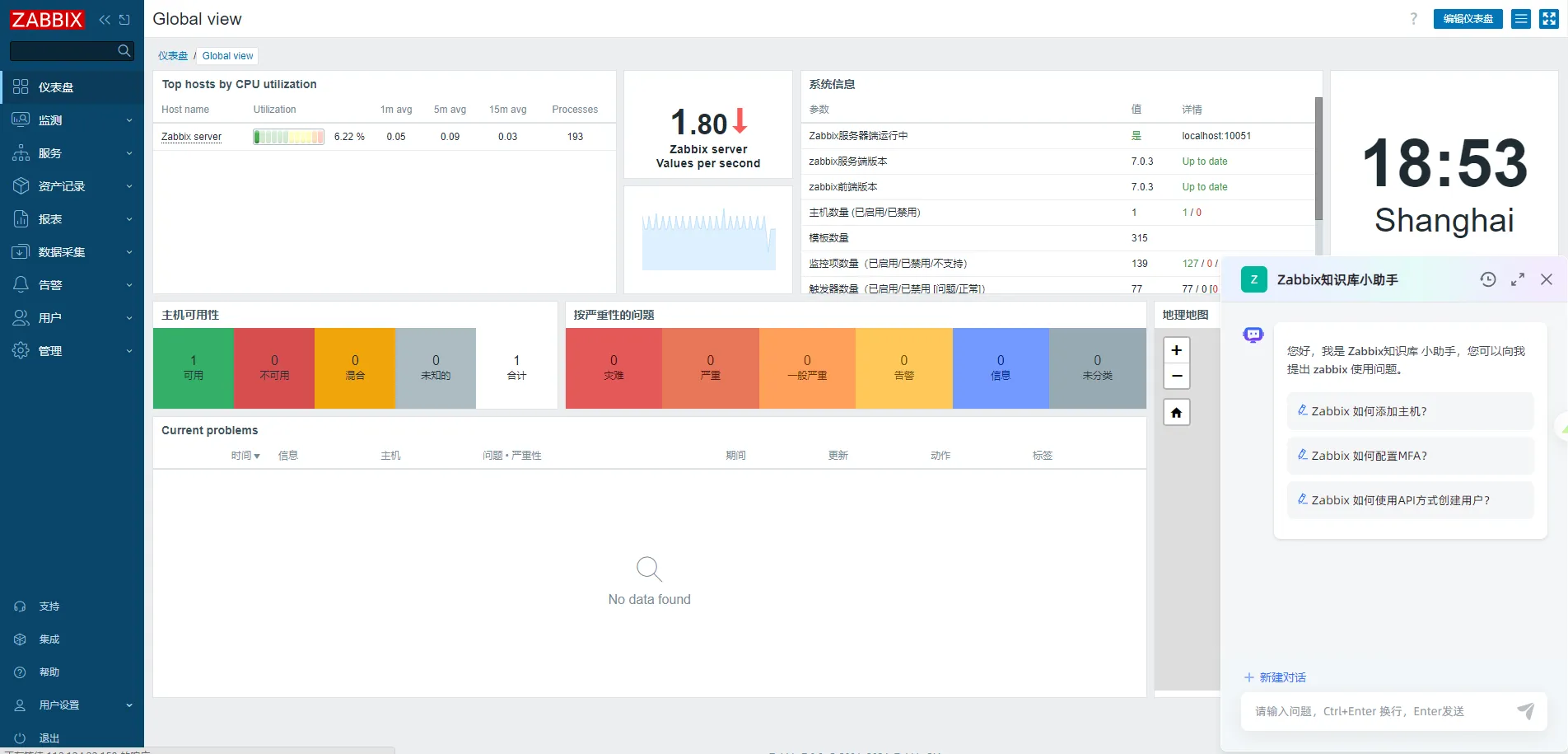
systemctl restart zabbix-server6 效果展示
7 Q&A
7.1 常见使用场景
① 可以将以往运维工程师的故障处理心得进行提炼,形成已知故障案例库并导入知识库。当相似问题重现时,能够快速检索到相关分析路径与恢复步骤,缩减故障排查时间。
② 如果可联网,也可以直接在Zabbix前端通过调用公有大模型提供检索服务,方便对检索互联网信息。
7.2 如何增强回答的准确性
① 知识文档优化,进行文本规范化处理,去除特殊字符、不相关及冗余信息,合理分段,提升文档可读性。
② 向量检索优化,自定义 embedding 模型,结合知识库数据量设置不同搜索模式,调整相似度值与 TOP 分段,精准定位所需内容。
③ 提示词优化,依据问答场景设置特定提示词,引导模型适应各种应用场景,提供贴心服务。
④ 模型层面优化,接入参数更多、性能更强且数据不断更新的模型,或按需接入用户自行微调的模型,满足个性化需求。